How to launch managed training
These interfaces create the same underlying managed jobs:
Install the training skill or continue with the method-specific managed guides below. For custom Python training loops, start with the Training API overview.
Methods
Supervised Fine Tuning - Text
Train text models with labeled examples of desired outputs
Supervised Fine Tuning - Vision
Train vision-language models with image and text pairs
Preference Optimization (DPO / ORPO)
Train on preferred and non-preferred response pairs using DPO or ORPO
Reinforcement Fine Tuning
Train models using custom reward functions for complex reasoning tasks
Free Reinforcement Fine-Tuning
When creating a Reinforcement Fine-Tuning job in the UI, look for the “Free tuning” filter in the model selection area: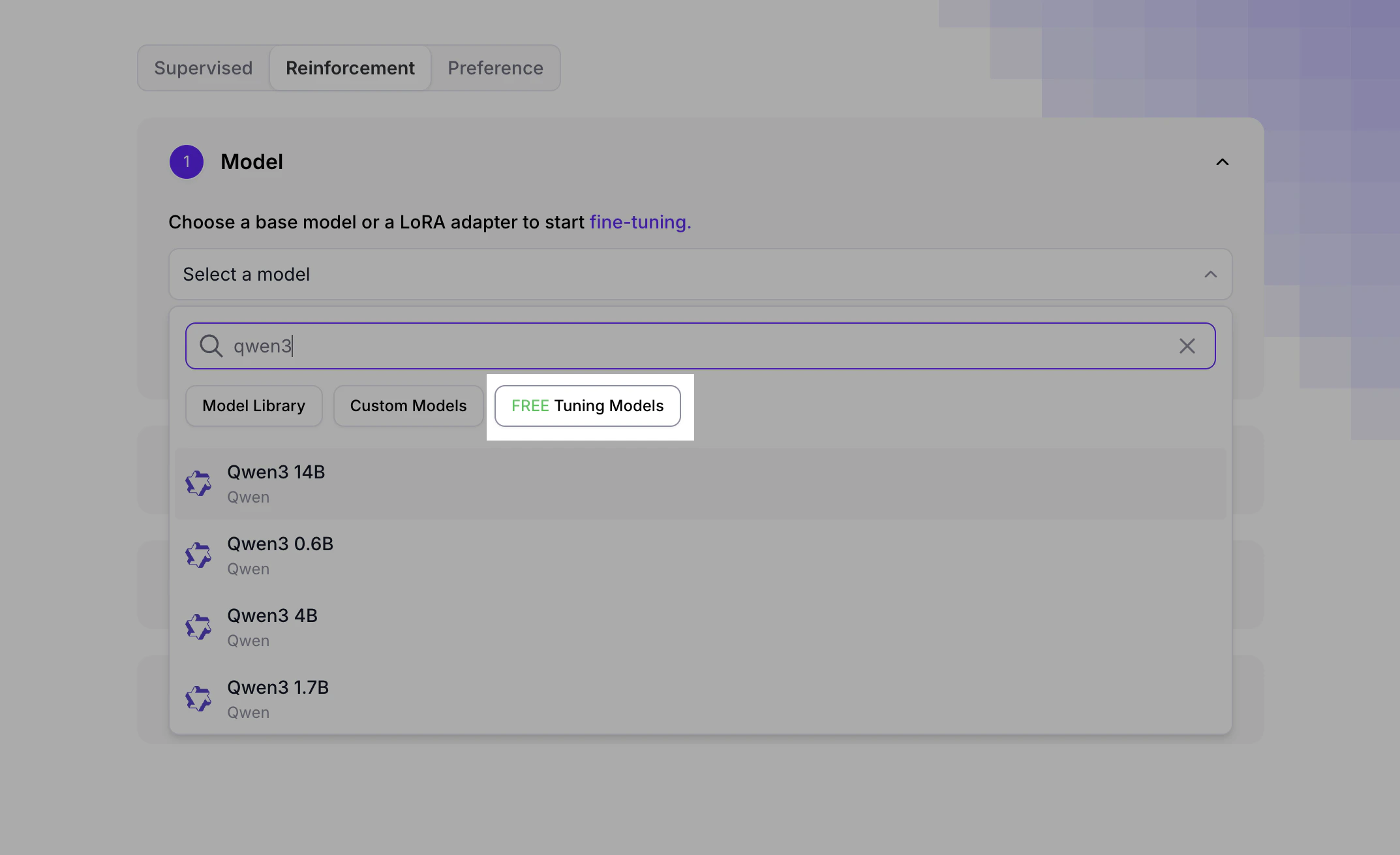
Supported base models
Fireworks supports fine-tuning for major open source model families, including DeepSeek, Qwen, Kimi, Gemma, GLM, and Llama. Eligibility is method and parameter-mode specific: a model can support SFT without supporting DPO, RFT, LoRA, or full-parameter training on the same shapes. Use the live Training Shapes method-support matrix before creating a job. Custom models uploaded by users are not automatically tunable. To use managed fine-tuning with an uploaded custom base model, the model must have a corresponding Hugging Face URL. Fireworks uses that URL to infer the training renderer and locate compatible training shapes. A custom model is supported only when Fireworks can resolve both a supported renderer and at least one compatible training shape. After the Hugging Face URL is set, tunability is refreshed by a background operation that runs about every 30 minutes, so the model may take up to 30 minutes to show asTunable: true. We are working to make this refresh faster.
The table below is generated from the live training shape registry. The “Max supported context length” is a catalog-level model maximum. For a job, use the maximum context of a shape that supports the selected method and tuning mode. Set it with firectl sftj create, firectl dpo-job create, or the corresponding RFT command.
To browse the broader catalog (including non-tunable inference models), visit the Model Library for text models or vision models.