- Data labeling and synthetic data generation
- Training smaller models with larger ones (distillation guide)
- Large-scale evaluations and benchmarking
- Document processing and more
Model compatibility
Not all models support the Batch API. Before submitting a batch job, verify your target model is batch-compatible.- Base Models – Any model that supports On-Demand Deployments in the Model Library
- Custom Models – Your uploaded or fine-tuned models built on a batch-compatible base model
If a model does not support batch inference, submitting a job may not produce an immediate error — the job can remain in a pending state and never schedule. Always verify compatibility before submitting.
- If validation failed, check your JSONL input — each line must be a complete, valid JSON object matching the request schema.
- Batch jobs wait to be scheduled in a “pending” state during the selected time window, so it may not run immediately.
- If the job has been “creating” a deployment for more than 30 minutes, contact support with your job ID.
- Confirm the model supports batch inference (see above).
- Check that your account has sufficient quota for batch jobs.
- Progress may pause while waiting on capacity. The job will resume automatically.
Getting Started
1. Prepare Your Dataset
1. Prepare Your Dataset
Datasets must be in JSONL format (one JSON object per line):Requirements:Save as
- File format: JSONL (each line is a valid JSON object)
- Size limit: Under 1GB
- Required fields:
custom_id(unique) andbody(request parameters)
batch_input_data.jsonl locally.2. Upload Your Dataset
2. Upload Your Dataset
- UI
- firectl
- HTTP API
You can simply navigate to the dataset tab, click 
Create Dataset and follow the wizard.3. Create a Batch Job
3. Create a Batch Job
- UI
- firectl
- HTTP API
Navigate to the Batch Inference tab and click “Create Batch Inference Job”. Choose your batch-eligible model from the dropdown selector:


4. Monitor Your Job
4. Monitor Your Job
- UI
- firectl
- HTTP API
View all your batch inference jobs in the dashboard: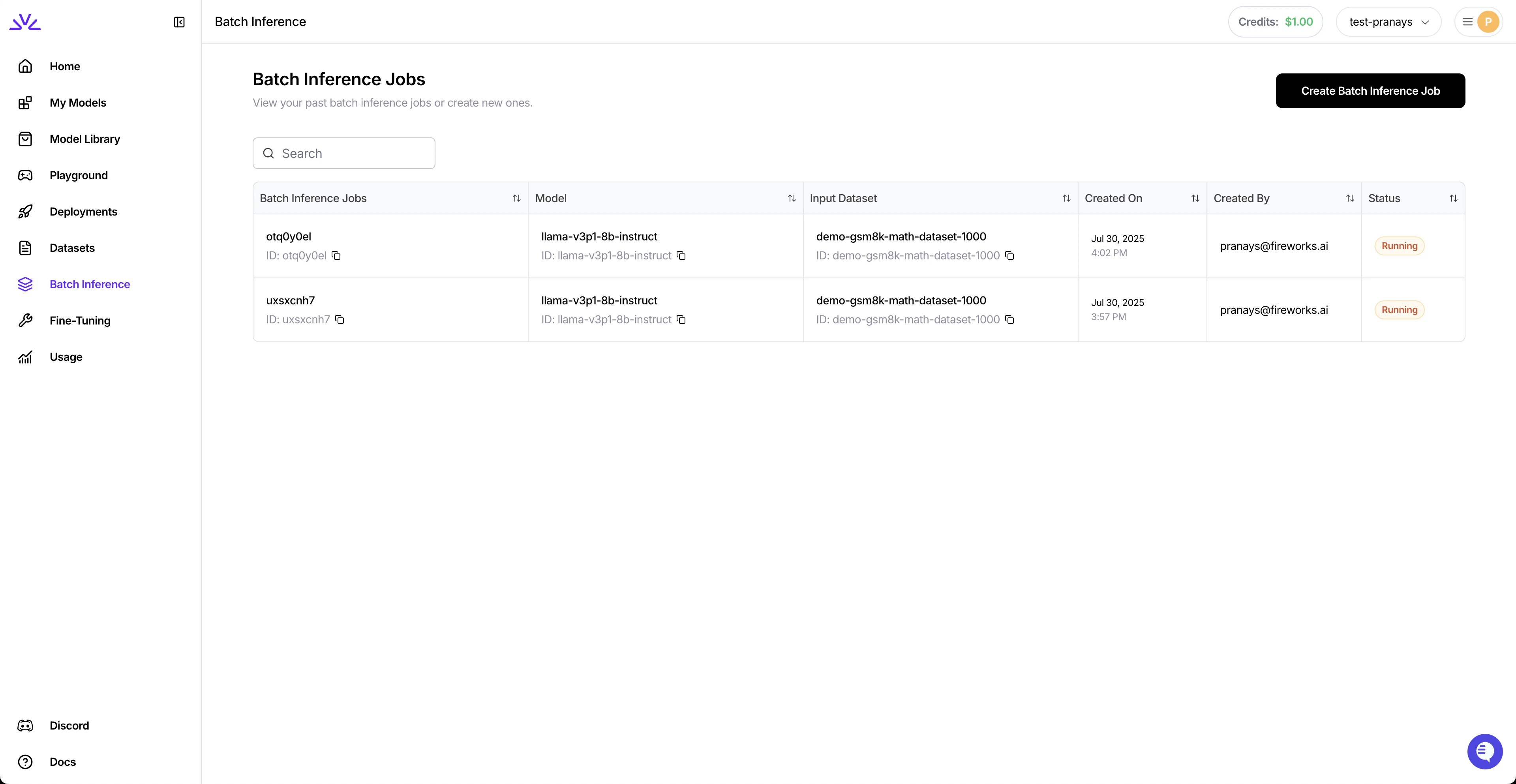
5. Download Results
5. Download Results
- UI
- firectl
- HTTP API
Navigate to the output dataset and download the results:
Reference
Job states
Job states
Batch jobs progress through several states:
| State | Description |
|---|---|
| VALIDATING | Dataset is being validated for format requirements |
| PENDING | Job is queued and waiting for resources |
| RUNNING | Actively processing requests |
| COMPLETED | All requests successfully processed |
| FAILED | Unrecoverable error occurred (check status message) |
| EXPIRED | Exceeded chosen time limit (12, 24, 48, 72 hrs). Completed requests are saved. |
Supported models
Supported models
- Base Models – Any model that supports On-Demand Deployments in the Model Library
- Custom Models – Your uploaded or fine-tuned models built on a batch-compatible base model
Limits and constraints
Limits and constraints
- Per-request limits: Same as Chat Completion API limits
- Input dataset: Max 1GB
- Output dataset: Max 8GB (job may expire early if limit is reached)
- Job expiration: Select from 12, 24, 48, 72 hours maximum in Optional Settings
Handling expired jobs
Handling expired jobs
Jobs expire after 24 hours. Completed rows are billed and saved to the output dataset.Resume processing:This processes only unfinished/failed requests from the original job.Download complete lineage:Downloads all datasets in the continuation chain.
Best practices
Best practices
- Validate thoroughly: Check dataset format before uploading
- Descriptive IDs: Use meaningful
custom_idvalues for tracking - Optimize tokens: Set reasonable
max_tokenslimits - Monitor progress: Track long-running jobs regularly
- Cache optimization: Place static content first in prompts
Next Steps
Prompt Caching
Maximize cost savings with automatic prompt caching
Fine-Tuning
Create custom models for your batch workloads
API Reference
Full API documentation for Batch API