Understanding LoRA
LoRA significantly reduces the computational and memory cost of fine-tuning large models by updating the LLM parameters in a low‑rank structure, making it particularly suitable for large models like LLaMA or DeepSeek. Fireworks AI supports LoRA tuning, allowing up to 100 LoRA adaptations to run simultaneously on a dedicated deployment without extra cost.List of Supported Models
We currently support fine-tuning Llama 3 models, Qwen 2/2.5 models, Qwen 3 non-MoE models, DeepSeek V3/R1 models, Gemma 3/4 models and Phi 3/4 models; as well as any custom model with these supported architectures. When you create a supervised fine tuning job in UI following the tutorial below, the list of models in the dropdown are all supported. You will notice that the LoRA models for those supported architecures are also available in the dropdown because we also support continue fine-tuning from existing LoRA models.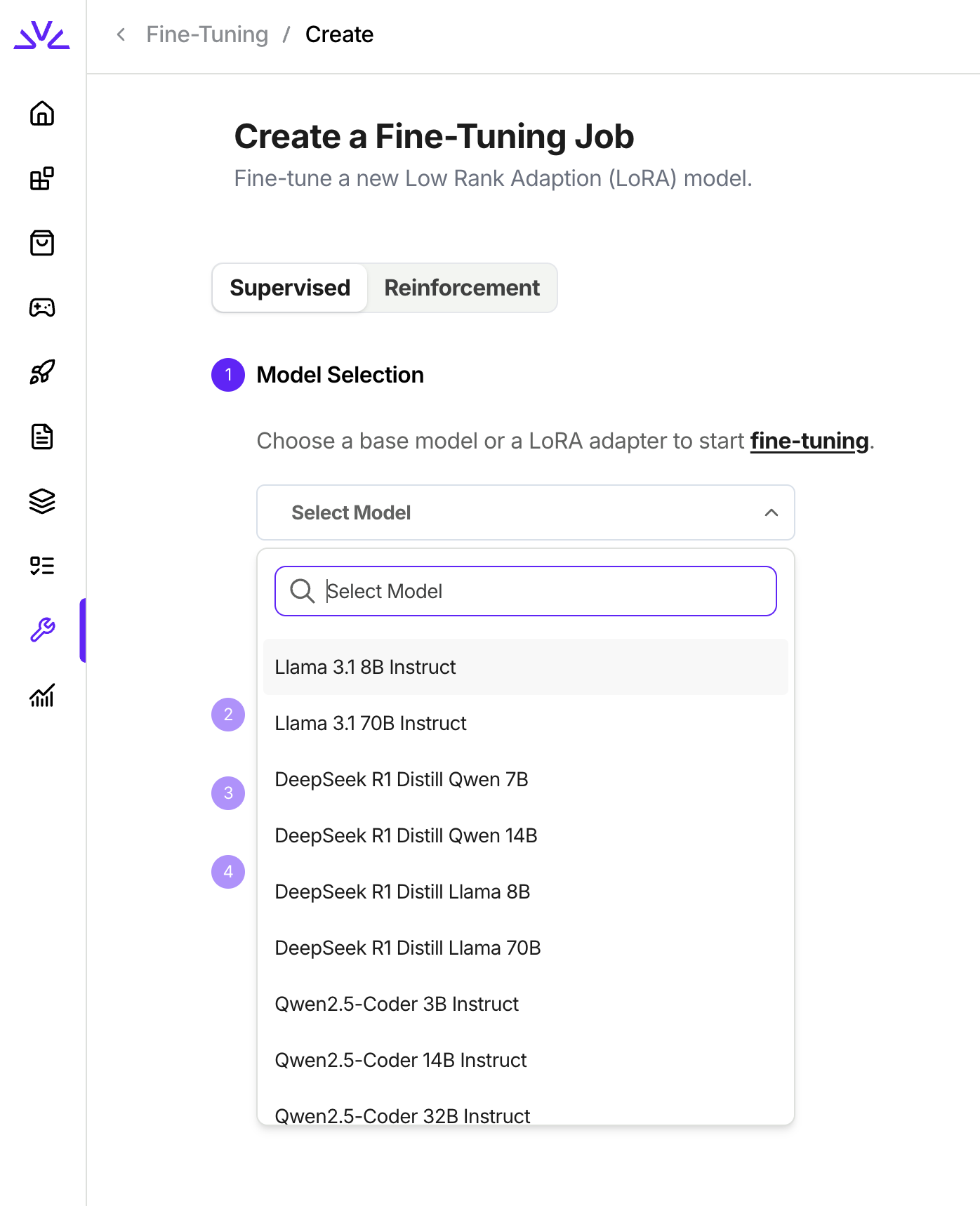
Step-by-Step Guide to Fine-Tuning with Fireworks AI
1. Preparing the Dataset
Datasets must adhere strictly to the JSONL format, where each line represents a complete JSON-formatted training example. Minimum Requirements:- Minimum examples needed: 3
- Maximum examples: Up to 3 million examples per dataset
- File format: JSONL (each line is a valid JSON object)
- Message Schema: Each training sample must include a
messagesarray, where each message is an object with two fields:role: one ofsystem,user, orassistantcontent: the message content, either a plain string or a list of OpenAI-style content parts such as[{"type": "text", "text": "..."}]. Both forms are accepted and can be mixed within the same dataset.
- Sample weight: Optional key
weightat the root of the JSON object. It can be any floating point number (positive, negative, or 0) and is used as a loss multiplier for tokens in that sample. If used, this field must be present in all samples in the dataset.
content as a list of OpenAI-style content parts (and mix it with the plain-string form):
trader_poe_sample_data.jsonl.
2. Uploading the Dataset to Fireworks AI
There are a couple ways to upload the dataset to Fireworks platform for fine tuning:firectl, Restful API , builder SDK or UI.
-
Upload dataset through UI
You can simply navigate to the dataset tab, click
Create Datasetand follow the wizard.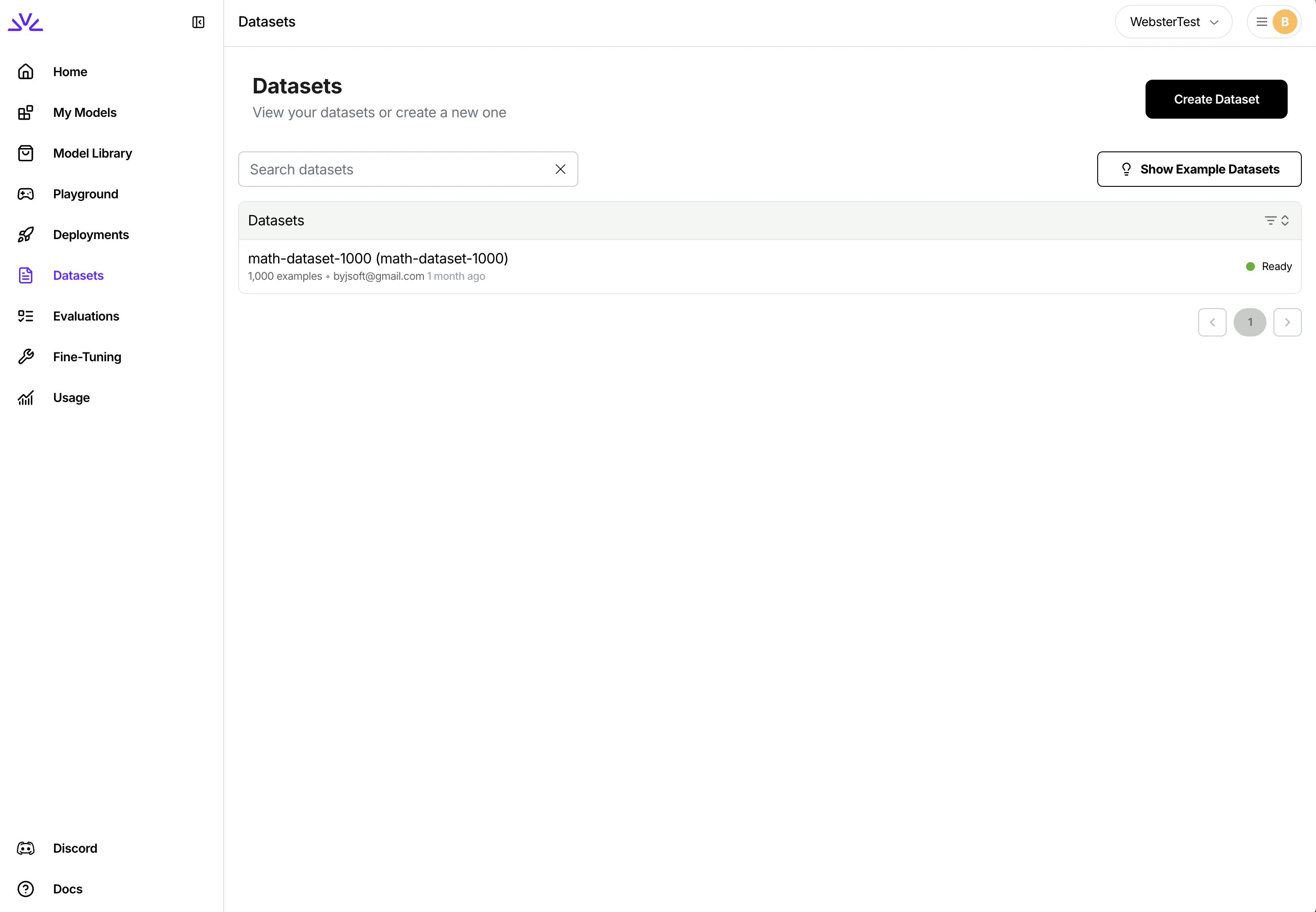
-
Upload dataset using
firectl
-
Upload dataset using
Restful APIYou need to make two separate HTTP requests. One for creating the dataset entry and one for uploading the dataset. Full reference here: Create dataset. Note that theexampleCountparameter needs to be provided by the client.
UI is more suitable for smaller datasets < 500MB while firectl might work better for bigger datasets.
3. Creating a Fine-Tuning Job
Similarly, there are a couple different approaches for creating the supervised fine tuning job. We highly recommend creating supervised fine tuning jobs viaUI . To do that, simply navigate to the Fine-Tuning tab, click Fine-Tune a Model and follow the wizard from there.
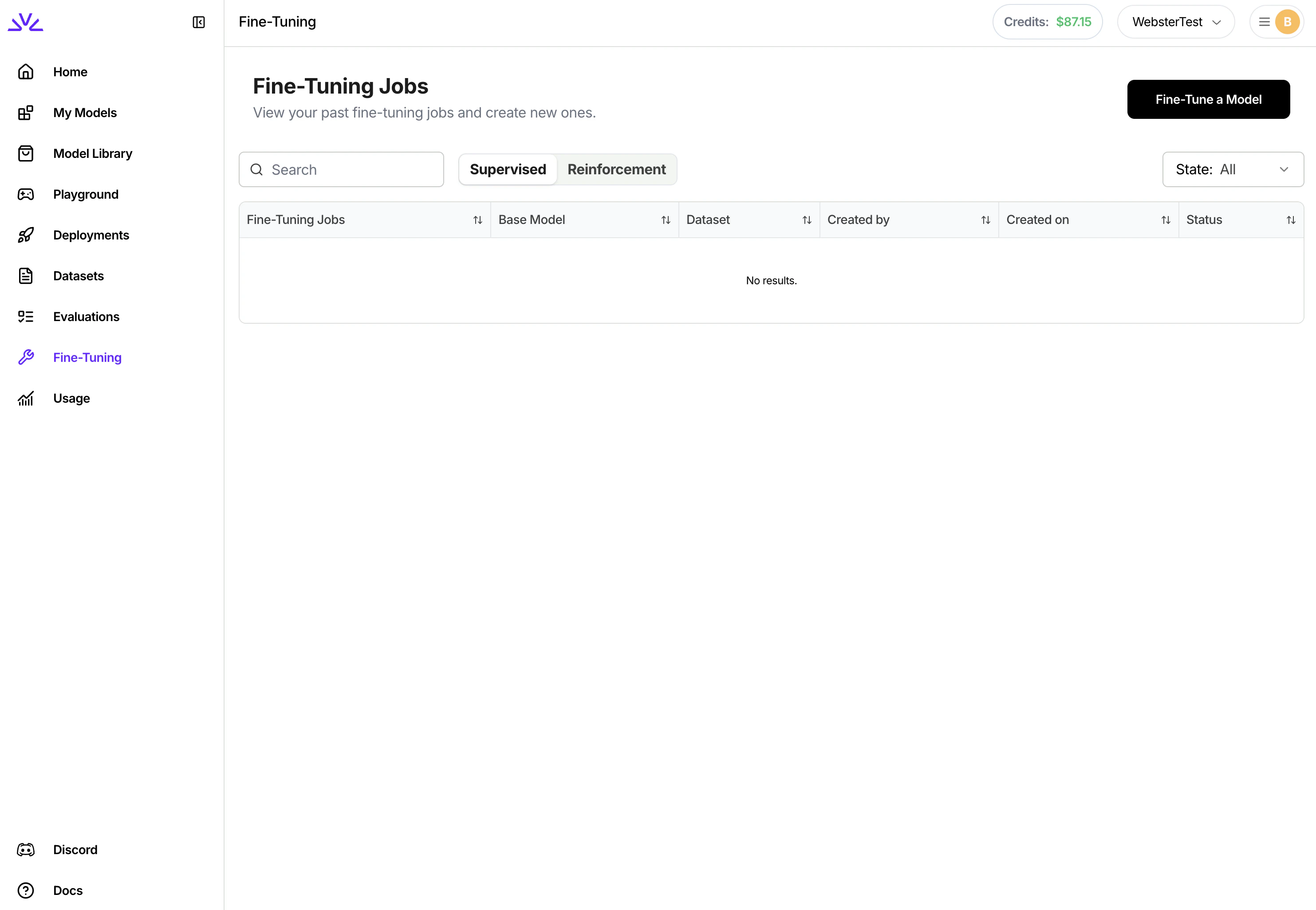
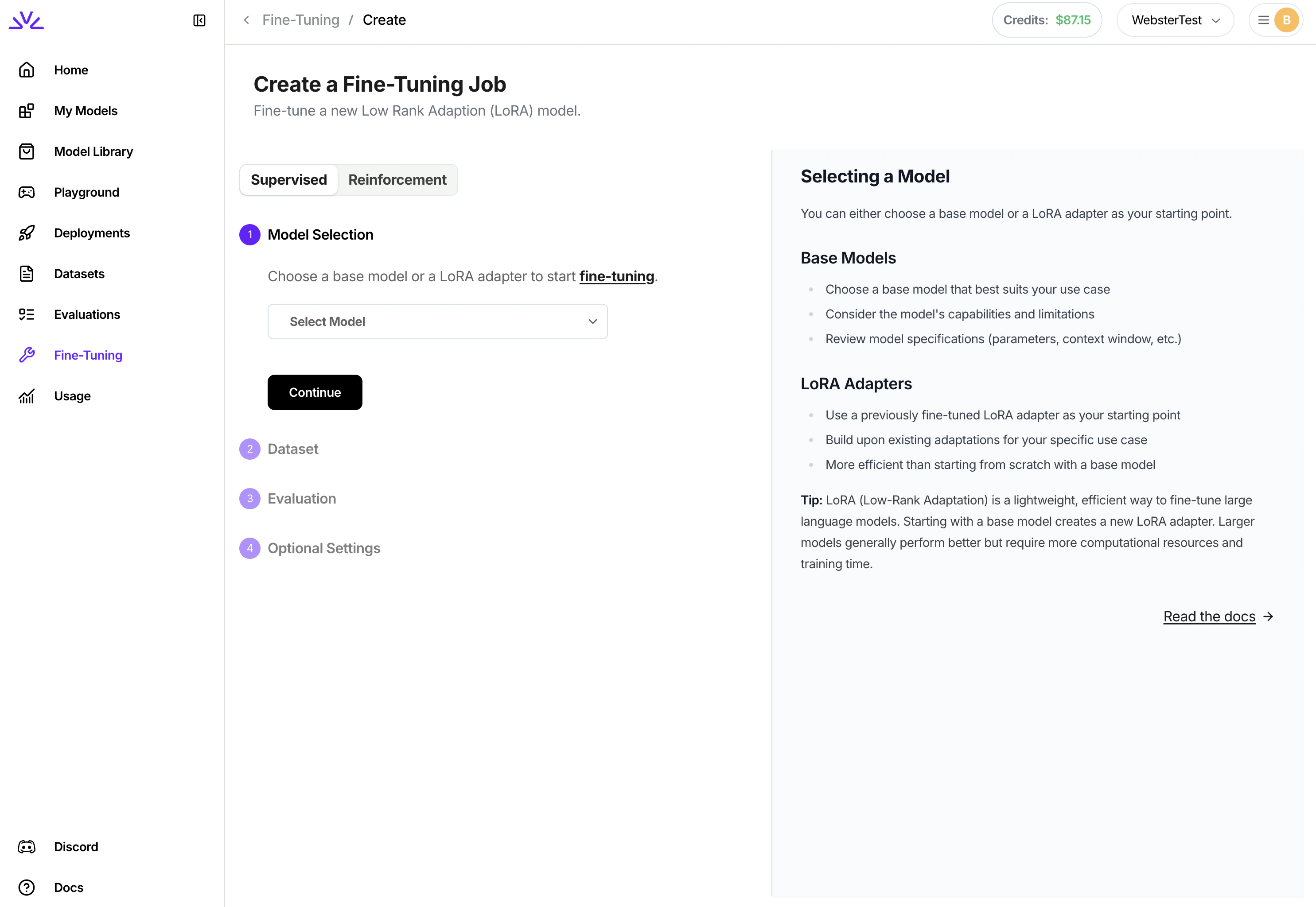
4. Monitoring and Managing Fine-Tuning Jobs
Once the job is created, it will show in the list of jobs. Clicking to view the job details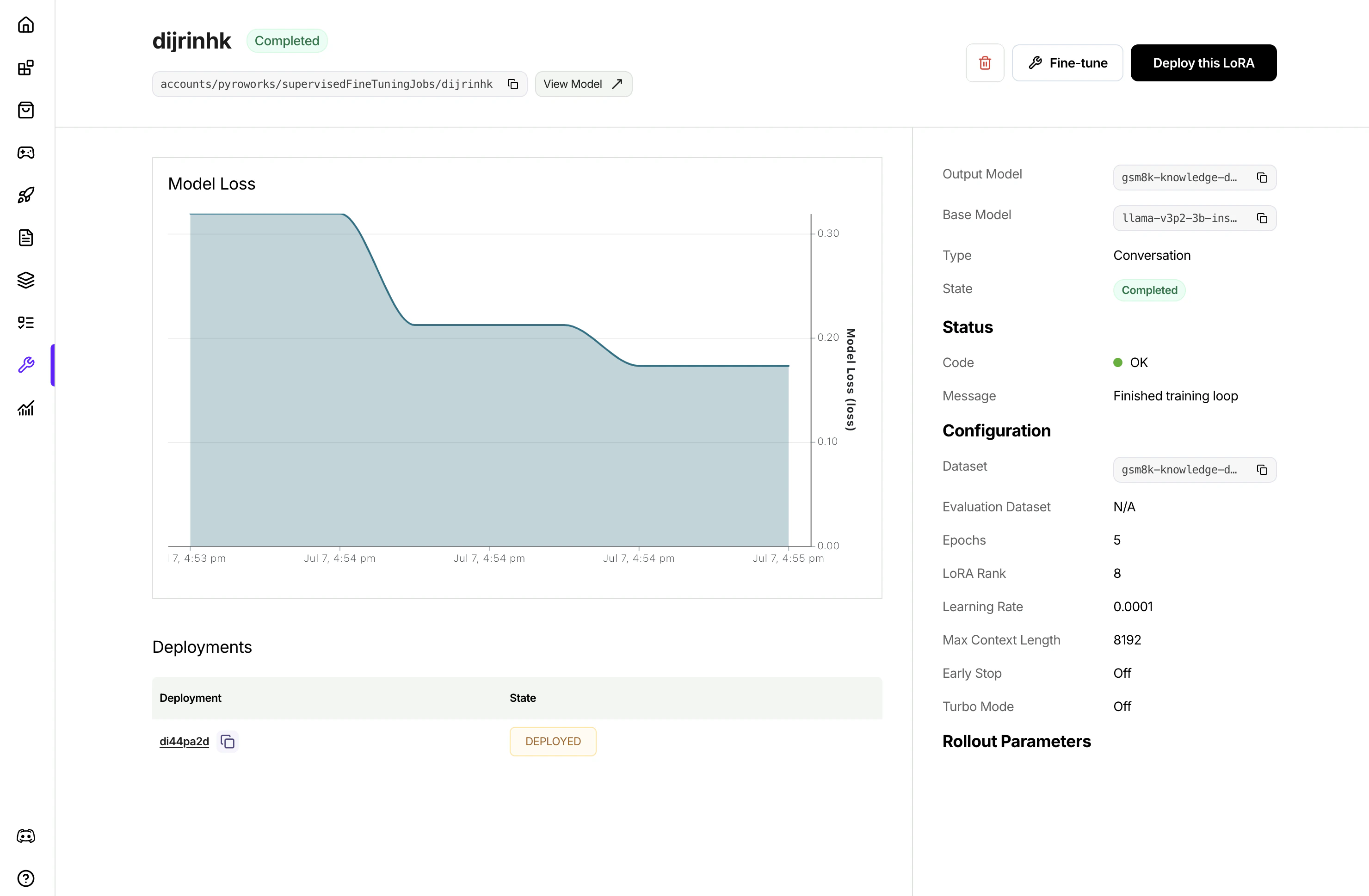
5. Deploying the Fine-Tuned Model
After fine-tuning is complete, you have three options for deploying the model.- Live-merge Deployment: Create a deployment by merging the LoRA weights into the base model directly, optimized for latency and speed. This is the recommended approach for most use cases.
- Multi-LoRA Deployment: Create a deployment with addons enabled, then deploy multiple LoRA models on top as addons. You can deploy 100s of LoRA models as addons onto a single deployment. Learn more about it here: multi-lora deployment
Deploy this LoRA button in the supervised fine tuning job details page or LoRA model details page, and follow the wizard.
6. Best Practices and Considerations
- Validate your dataset thoroughly before uploading.
- Use a higher
loraRankfor larger model capacity (e.g., 8 for complex tasks). If loraRank is higher, consider using smaller learning rate too. - Monitor job health and logs for errors.
- Do not set
earlyStop; the field is deprecated and early stopping is not supported by managed training. - Use descriptive names for dataset IDs and models for clarity.
How multi-turn conversations are split for training
When a conversation in your dataset has more than one assistant turn (common with agentic multi-turn data), Fireworks does not always feed it to the trainer as a single sequence. Depending on the base model’s chat template, one source conversation can be expanded (unrolled) into several training records, each training on a different assistant turn. Thetrain_on_what setting controls which assistant content contributes to the loss, and the model’s renderer controls whether the conversation is split or kept whole.
You can see the resolved value on every rendered record in render_samples.jsonl (see Debug SFT tokenization):
train_on_what values
all_assistant_messages is the default. It trains on every assistant message in the conversation (subject to the per-message weight filter described in Weighted Training), while system, user, and tool-result messages stay as zero-weight context.
Splitting is model-dependent, not always one record per assistant turn
The reason is train/inference consistency. At inference time some chat templates strip earlier turns’ thinking traces from the visible history, keeping only the finalcontent. To match that at training time, Fireworks expands the conversation into per-turn records so each record presents history exactly as the model would see it at inference. Templates that keep earlier-turn thinking do not need this and can train the whole conversation in one record. The observed behavior by model family:
The base models actually available for SFT are listed in this page’s List of Supported Models section; reconcile a family’s typical behavior above against that list before relying on it.
These are typical behaviors, not guarantees. Because splitting is determined by the model’s chat template, always confirm against your own rendered output (see Verify the split) rather than assuming a family default. In particular, when moving from a Qwen-class model to a Kimi-class one, do not expect the one-record-per-turn behavior to carry over.
Because behavior is model-specific, the reliable way to know what your dataset produces is to inspect
render_samples.jsonl for your actual job (see Verify the split below), rather than assuming a fixed record count.
How loss masking works across turns
Within any single rendered record, masking is per token viatoken_weights (rendered order) and training_loss_weights (the next-token-shifted array actually used by the trainer):
system,user, and tool-result tokens have weight0(context only).- Assistant tokens selected by
train_on_whathave positive weight and contribute to loss. - A per-message
weight: 0removes that assistant message’s tokens from the loss even though they remain in context. Message-level weights accept only0or1(see Weighted Training). - When a conversation is split, earlier assistant turns that a later record only needs as context are re-rendered with weight
0in that later record.
If splitting produces a record whose assistant turns are all zero-weight (for example, you set per-message
weight: 0 on every turn except the last), that all-masked record has nothing to train on. Such records are dropped and the surviving records are re-indexed, so you may see fewer records than assistant turns and a split_index that no longer matches the original turn position. Worked example
Source conversation with two assistant turns:-
split_index 0trains on the first assistant turn only. -
split_index 1trains on the second assistant turn, with the first turn kept as zero-weight context and its thinking trace stripped to match inference:
split_index 0) that trains on both assistant turns in one sequence.
Because the splitting case re-renders earlier turns as context, the total rendered/processed token count can exceed the raw uploaded token count.
Split records are independent training examples billed on processed tokens
Each rendered record is an independent training example. When a conversation is split, Fireworks expands it into several separate training examples (one per trained assistant turn), each counted individually in the record total, and does not reassemble them back into the source conversation during training. This is why a dataset can render to more records than it has source rows (for example, 300 source rows expanding to 355 records). Multi-turn conversations are unrolled into multiple single-turn training examples so that each example presents history exactly as the model sees it at inference (see fine-tuning models). SFT is billed on the tokens processed, which equals the rendered (tuned) token count times the number of epochs (see the pricing page). For multi-turn data the rendered token count is larger than the raw uploaded count because earlier-turn context is duplicated across the expanded examples (see fine-tuning models). Records that are dropped for being fully weight-0 produce no rendered example and are therefore not billed. Do not estimate SFT cost from the raw upload size for multi-turn datasets; instead inspectrender_samples.jsonl to see the rendered examples that actually run through training.
Verify the split with render samples
To confirm exactly how your dataset expands for a specific base model, do not rely on a formula. Run the job, downloadrender_samples.jsonl, and count the records per source row:
1) means that model’s renderer kept the conversation whole. Counts greater than 1 mean the renderer split that conversation into one record per assistant turn. For the full field reference and per-token inspection, see Debug SFT tokenization.
Appendix
Python builder SDK references
Restful API references
firectl references